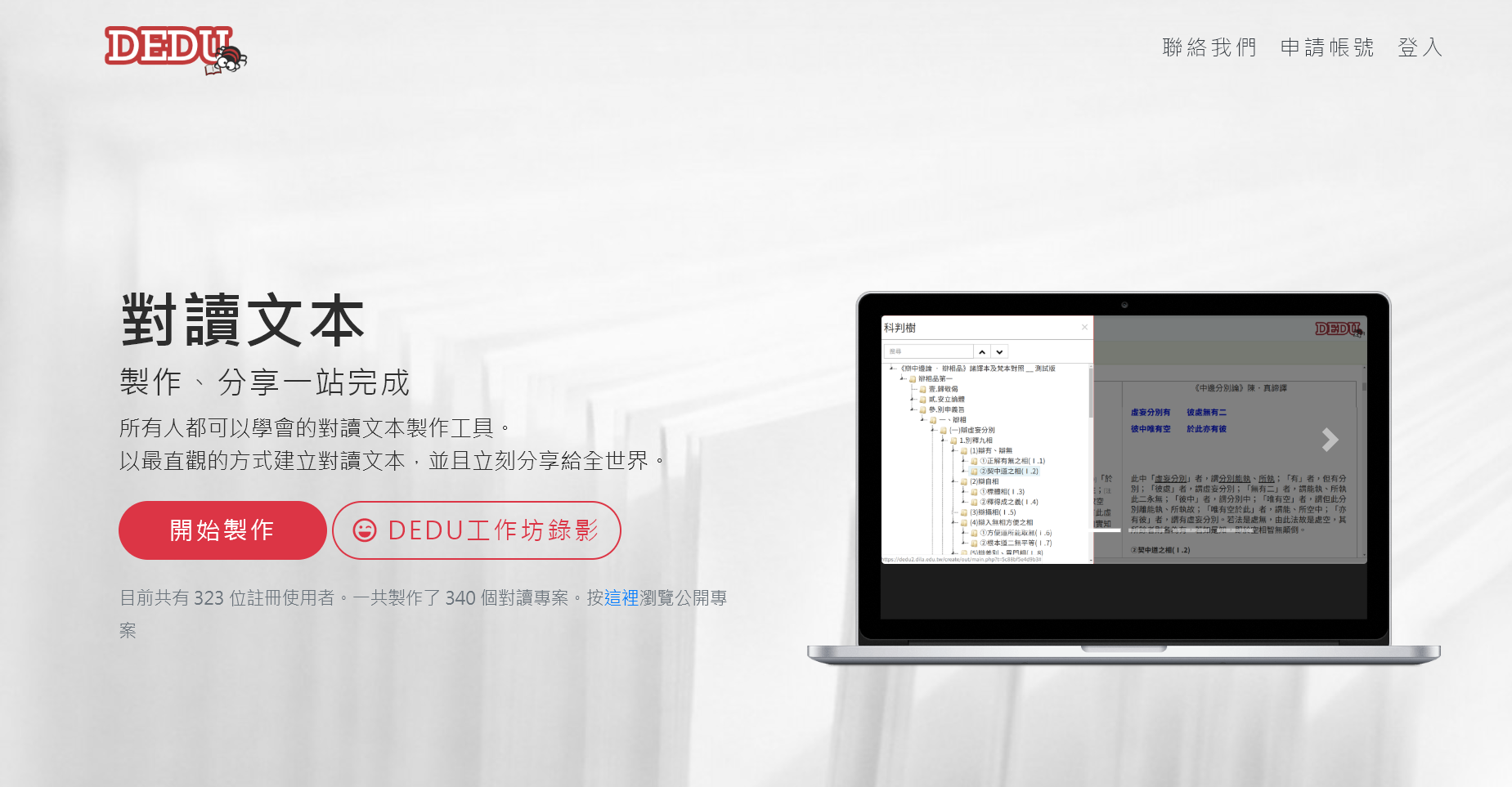
Feature:
Digitalized index to footnotes of the 6-volumes Japanese translation of the Dīrgha-āgama.
About:
The Āgama Research Group at DILA has digitized, edited and supplemented an unpublished index to footnotes of the 6-volumes Japanese translation of the Dīrgha-āgama (《長阿含經》Taishō 1) in the format of XML, HTML and pdf.
Content:
Reference:
Karashima Seishi (辛嶋静志)、Okayama Hajime (丘山新)、Kamitsuka Yoshiko (神塚淑子)、Kanno Hiroshi (菅野博史)、Sueki Fumihiko (末木文美士)、Hikita Hiromichi (引田弘道) 以及 Matsumura Takumi (松村巧),Gendaigo yaku agon kyōten: Jōagongyō. 現代語訳「阿含経典」, Tokyo: Hirakawa Shuppansha (平河出版社),1996-2005,六冊。
This large translation project was the joint effort of sinologically trained linguists and philologists trained in Indology and Buddhist studies. Their combined expertise resulted in rich research footnotes that deal with problematic terminology and readings from a perspective that takes into account both linguistic and content aspects of the Āgama collection. This makes the index to the words and passages discussed in the footnotes particularly useful for scholars of the early Buddhist Āgamas and for scholars working on the Chinese translations of Buddhist texts in general.
The 6-volumes translation is based on an earlier serialized translation that was originally published in monthly instalments in Gekkan Āgama (月刊アーガマ). The incomplete unpublished index was first prepared on the basis of this serialised translation. The person responsible for assembling the original index – compiled by a group of Japanese students – is Eiichi Enomoto (榎本榮一), formerly editor at Hirakawa Shuppansha (平河出版社). The publisher Hirakawa Shuppansha (平河出版社) has granted its permission to use, modify and make freely available the index.
The draft version has been first digitized, then matched with the 6-volumes edition, supplemented and corrected wherever necessary. The present index covers all words and phrases significantly discussed in the footnotes of the 6-volumes edition.